
Hadoop Introduction
Hadoop is an open source framework for distributed fault-tolerant data storage and batch processing. It allows you to write applications for processing really huge data sets across clusters of computers using simple programming model with linear scalability on commodity hardware. Commodity hardware means cheaper hardware than the dedicated servers that are sold by many vendors. Linear scalability means that you have only to add more machines (nodes) to the Hadoop cluster.
The key concept for Hadoop is move-code-to-data, that is, data is distributed across the nodes of the Hadoop cluster and the applications (the jar files) are later sent to that nodes instead of vice versa (as in Java EE where applications are centralized in a application server and the data is collected to it over the network) in order to process the data locally.
At its core, Hadoop has two parts:
· Hadoop Distributed File System (HDFS™): a distributed file system that provides high-throughput access to application data.
· YARN (Yet Another Resource Negotiator): a framework for job scheduling and cluster resource management.
As you can see in the very definition of the Apache Hadoop website (what is Apache Hadoop?), Hadoop offers as a third component Hadoop MapReduce, a batch-based, distributed computing framework modeled after Google’s paper on MapReduce. It allows you to parallelize work over a large amount of raw data by splitting the input dataset into independent chunks which are processed by the map tasks (initial ingestion and transformation) in parallel, whose outputs are sorted and then passed to the reduce tasks (aggregation or summarization).
In the previous version of Hadoop (Hadoop 1), the implementation of MapReduce was based on a master JobTracker, for resource management and job scheduling/monitoring, and per-node slaves called TaskTracker to launch/teardown tasks. But it had scalability problems, specially when you wanted very large clusters (more than 4,000 nodes).
So, MapReduce has undergone a complete overhaul and now is called MapReduce 2.0 (MRv2), but it is not a part by itself, currently, MapReduce is a YARN-based system. That’s the reason why we can say that Hadoop has two main parts: HDFS and YARN.
Hadoop ecosystem
Besides the two core technologies, the distributed file system (HDFS) and Map Reduce (MR), there are a lot of projects that expand Hadoop with additional useful technologies, in such a way that we can consider all of them an ecosystem around Hadoop.
Next, a list of some of these projects, organized by some kind of categories:
- Data Ingestion: to move data from and into HDFS
- Flume: a system for moving data into HDFS from remote systems using configurable memory-resident daemons that watch for data on those systems and then forward the data to Hadoop. For example, weblogs from multiple servers to HDFS.
- Sqoop: a tool for efficient bulk transfer of data between structured data stores (such as relational databases) and HDFS.
- Data Processing:
- Pig: a procedural language for querying and data transform with scripts in a data flow language call PigLatin.
- Hive: a declarative SQL-like kanguage.
- Spark: an in-memory distributed data processing that breaks problems up over all of the Hadoop nodes, but keeps the data in memory for better performance and can be rebuilt with the details stored in the Resilient Distributed Dataset (RDD) from an external store (usually HDFS).
- Storm: a distributed real-time computation system for processing fast, large streams of data.
- Data Formats:
- Avro: a language-neutral data serialization system. Expressed as JSON.
- Parquet: a compressed columnar storage format that can efficiently store nested data
- Storage:
- HBase: a scalable, distributed database that supports structured data storage for large tables.
- Accumulo: a scalable, distributed database that supports structured data storage for large tables.
- Coordination:
- Zookeeper: a high-performance coordination service for distributed applications.
- Machine Learning:
- Mahout: a scalable machine learning and data mining library: classification, clustering, pattern mining, collaborative filtering and so on.
- Workflow Management:
- Oozie: a service for running and scheduling workflows of Hadoop jobs (including Map-Reduce, Pig, Hive, and Sqoop jobs).
Hadoop installation
To install Hadoop on a single machine to try it out, just download the compressed file for the desired version and unpack it on the filesystem.
Prerequisites
There is some required software for running Apache Hadoop:
- Java. It’s also necessary to inform Hadoop where Java is via the environment variable JAVA_HOME
- ssh: I have Ubuntu 14.04 that comes with ssh, but I had to manually install a server.
- On Mac OSX, make sure Remote Login (under System Preferences -> File Sharing) is enabled for the current user or for all users.
- On Windows, the best option is to follow the instructions at the Wiki: Build and Install Hadoop 2.x or newer on Windows.
|
1 2 3 4 5 6 |
$ java -version java version "1.8.0_31" Java(TM) SE Runtime Environment (build 1.8.0_31-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode) $ echo $JAVA_HOME /usr/lib/jvm/java-8-oracle |
|
1 2 3 4 |
$ which ssh /usr/bin/ssh $ which sshd /usr/sbin/sshd |
Download and install
To get a Hadoop distribution, download a recent stable release from one of the Apache Download Mirrors.
There are several directories, for the current, last stable, last v1 stable version and so on. Basically, you’ll download a tar gzipped file named hadoop-x.y.z.tar.gz, for instance: hadoop-2.6.0.tar.gz.
You can unpack it wherever you want and then point the PATH to that directory. For example:
|
1 2 3 4 |
$ tar xzf hadoop-2.6.0.tar.gz $ $ export HADOOP_HOME=~/Applications/hadoop-2.6.0 $ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin |
Now you can verify the installation by typing hadoop version:
|
1 2 3 4 5 6 7 8 |
$ hadoop version Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using ~/Applications/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar $ |
Configuration
Hadoop has three supported modes:
- Local (Standalone) Mode: a single Java process with daemons running. For development testing and debugging.
- Pseudo-Distributed Mode: each Hadoop daemon runs in a separate Java process. For simulating a cluster on a small scale.
- Fully-Distributed Mode: the Hadoop daemons run on a cluster of machines. If you want to take a look, see the oficial documentation: Hadoop MapReduce Next Generation – Cluster Setup.
In standalone mode, there is no further action to take, the default properties are enough and there are no daemons to run.
In pseudodistributed mode, you have to set up your computer as described at Hadoop MapReduce Next Generation – Setting up a Single Node Cluster. But let’s review the steps needed.
You need at least a minimum configuration with four files in HADOOP_HOME/etc/hadoop/:
- core-site.xml. Common configuration, default values at Configuration: core-default.xml
- hdfs-site.xml. HDFS configuration, default values at Configuration: hdfs-default.xml
- mapred-site.xml. MapReduce configuration, default values at Configuration: mapred-default.xml
- yarn-site.xml. YARN configuration, default values at Configuration: yarn-default.xml
|
1 2 3 4 5 6 7 8 |
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8020</value> </property> </configuration> |
fs.defaultFS replaces the deprecated fs.default.name whose default value is file://
|
1 2 3 4 5 6 7 8 |
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
dfs.replicationis the default block replication, unless other is specified at creation time. The default value is 3, but we use 1 because we have only one node.
Other useful values are:
dfs.namenode.name.dir, local path for storing the fsimage by the NN (defaults to file://${hadoop.tmp.dir}/dfs/name with hadoop.tmp.dir configurable at core-site.xml with default value /tmp/hadoop-${user.name})
dfs.datanode.data.dir, local path for storing blocks by the DN (defaults to file://${hadoop.tmp.dir}/dfs/data)
|
1 2 3 4 5 6 7 8 |
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
mapreduce.framework.name, the runtime framework for executing MapReduce jobs: local, classic or yarn.
Other useful values are:
mapreduce.jobtracker.system.dir, the directory where MapReduce stores control files (defaults to ${hadoop.tmp.dir}/mapred/system).
mapreduce.cluster.local.dir, the local directory where MapReduce stores intermediate data files (defaults to ${hadoop.tmp.dir}/mapred/local)
|
1 2 3 4 5 6 7 8 9 10 11 |
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
yarn.resourcemanager.hostname, the host name of the Resource Manager.
yarn.nodemanager.aux-services, list of auxiliary services executed by the Node Manager. The value mapreduce_shuffle is for the Suffle/Sort in MapReduce that is an auxilary service in Hadoop 2.x.
Configuring SSH
Pseudodistributed mode is like fully distributed mode with a single host: localhost. In order to start the daemons on the set of hosts in the cluster, SSH is used. So we’ll configure SSH to log in without password.
Remember that you need to have SSH installed and a server running. On Ubuntu, try this if you need so:
|
1 |
$ sudo apt-get install ssh |
Now create a SSH key with an empty passprhase
|
1 2 |
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa_hadoop $ cat ~/.ssh/id_rsa_hadoop.pub >> ~/.ssh/authorized_keys |
Finally, test if you can connect without a pasword by trying:
|
1 |
$ ssh localhost |
First steps with HDFS
Before using HDFS for the first time, some steps must be performed:
Formatting the HDFS filesystem
Just run the following command:
|
1 |
$ hdfs namenode -format |
Starting the daemons
To start the HDFS, YARN, and MapReduce daemons, type:
|
1 2 3 |
$ start-dfs.sh $ start-yarn.sh $ mr-jobhistory-daemon.sh start historyserver |
You can check what processes are running with the Java’s jps command:
|
1 2 3 4 5 6 7 8 |
$ jps 25648 NodeManager 25521 ResourceManager 25988 JobHistoryServer 25355 SecondaryNameNode 25180 DataNode 26025 Jps $ |
Stopping the daemons
Once it’s over, you can stop the daemons with:
|
1 2 3 |
$ mr-jobhistory-daemon.sh stop historyserver $ stop-yarn.sh $ stop-dfs.sh |
Creating A User Directory
You can create a home directory for a user with the next command:
|
1 |
$ hadoop fs -mkdir -p ~/Documents/hadoop-home/ |
Other Hadoop installations
There are another way to get installed Hadoop, that is, using companies that provide products that include Apache Hadoop or some kind of derivatives:
- Amazon Elastic MapReduce (Amazon EMR)
- Cloudera’s Distribution including Apache Hadoop (CDH)
- Hortonworks Data Platform Powered by Apache Hadoop (HDP)
- MapR Technologies
- Pivotal HD
Hadoop Distributed File System (HDFS)
The HDFS filesystem designed for distributed storage of very large files (hundreds of megabytes, gigabytes, or terabytes in size) and distributed processing using commodity hardware. It is a hierarchical UNIX-like file system, but internally it splits large files into blocks (with size from 32MB to 128MB, being 64MB the default), in order to perform a distribution and a replication of these blocks among the nodes of the Hadoop cluster.The applications that use HDFS usually write data once and read data many times.
The HDFS has two types of nodes:
- The master NameNode (NN), that stores the filesystem tree and the metadata for locating the files and directories in the tree that are actually located in the DataNodes. It stores this information in memory, however, to ensure against data loss, it’s also saved to disk using two files: the namespace image and the edit log.
- fsimage: a point in time snapshot of what HDFS looks like.
- edit log: the deltas or changes to HDFS since the last snapshot.
Both are prediodically merged.
- The DataNodes (DN), that are responsible for serving the actual file data (once the client knows which one to use after contacting the NameNode). They also sends heatbeats every 3 seconds (by default) to the NN and block reports every 1 hour (by default) to the DN both for maintenance purposes.
There is also a node poorly named Secondary NameNode that is not a failover node nor a backup node, it periodically merges the namespace image with the edit log to prevent the edit log from becoming too large. Thus, the best name for it is Checkpoint Node.
The Command-Line Interface
Once you have installed Hadoop, you can interact with HDFS, as well as other file systems that Hadoop supports (local filesystem, HFTP FS, S3 FS, and others), using the command line. The FS shell is invoked by:
|
1 |
$ hadoop fs <args> |
Provided to you have hadoop in the PATH as we saw above.
You can find a list of available commands at File System Shell.
You can perform operations like:
- copyFromLocal (putting files into HDFS)
- copyToLocal (getting files form HDFS)
- mkdir (creating directories in HDFS)
- ls (list files in HDFS)
Data exchange with HDFS
Hadoop is mainly written in Java, being the core class for HDFS the abstract class org.apache.hadoop.fs.FileSystem, that represents a filesystem in Hadoop. The several concrete subclasses provide implementations from local filesystem (fs.LocalFileSystem) to HDFS (hdfs.DistributedFileSystem), or Amazon S3 (fs.s3native.NativeS3FileSystem) and many more (read-only HTTP, FTP server, …)
Reading data
Reading data using the Java API involves to obtain the abstract FileSystem via one of the factory methods (get()), or the convenient method for retrieving the local filesystem (getLocal()):
public static FileSystem get(Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf, String user)
throws IOException
public static LocalFileSystem getLocal(Configuration conf) throws IOException
And then obtain an input stream for a file (that can be later be closed):
public FSDataInputStream open(Path f) throws IOException
public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException
With these methods on hand, the flow of the data in HDFS will be the next:
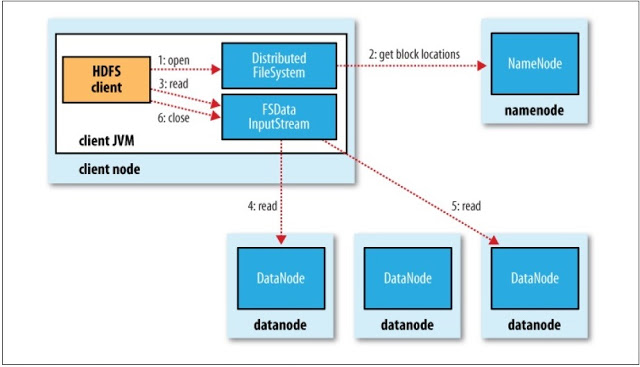
Reading from HDFS
- The client calls the open() method to read a file. A DistributedFileSystem is returned.
- The DistributedFileSystem asks the NameNode for the block locations. The NameNode returns an ordered list of the DataNodes that have a copy of the block (sorted by proximity to the client). The DistributedFileSystem returns a FSDataInputStream to the client for it to read data from
- The client calls read() on the input stream
- The FSDataInputStream reads data for the client from the DataNode until there is no more data in that node.
- The FSDataInputStream will manage the closing and opening connection to DataNodes for serving data to the client in a transparently way. It also manages validation (checksum) and errors (by trying to read data from a replica)
- When the client has finished reading, it calls close() on the FSDataInputStream
Writing data
The Java API allows you to create files with create methods (that, by the way, also create any parent directories of the file that don’t already exist). The API also includes a Progressable interface to be notified of the process of the data being written to the datanodes. It’s also possible to append data to an existing file, but this functionality is optional (S3 doesn’t support it from the time being)
public FSDataOutputStream create(Path f) throws IOException
public FSDataOutputStream append(Path f) throws IOException
The output stream will be used for writing the data. Furthermore, the FSDataOutputStream can inform of the current position in the file.
The flow of the data written to HDFS with these methods is the next:
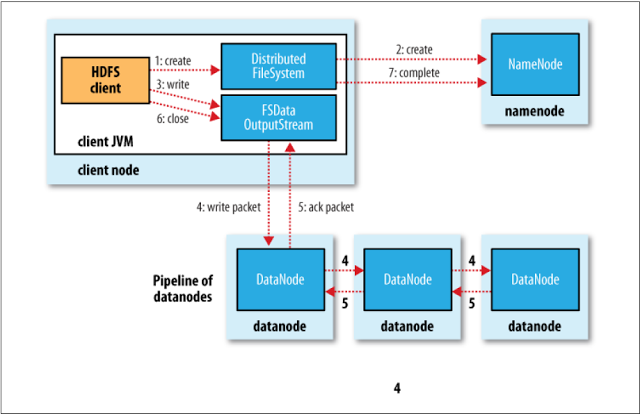
Writing to HDFS
- The client creates the file by calling create() on DistributedFileSystem.
- DistributedFileSystem makes an RPC call to the namenode to create a
new file in the filesystem’s namespace, with no blocks associated with it. The NameNode checks file existence and permission, throwing IOException if theres is any problem, otherwise, it returns a FSDataOutputStream for writing data to. - The data written by the client is splitted into packets that are sent to a data queue.
- The data queue is consumed by the Data Streamer which streams the packets to a pipeline of DataNodes (one per replication factor). Each DataNode stores the packet and send it to the next DataNode in the pipeline.
- There is another queue, ack queue, that contains the packets that are waiting for acknowledged by all the datanodes in the pipeline. If a DataNode fails in a write operation, the pipeline will be re-arranged transparently for the client.
- When the client has finished writing data, it calls close() on the stream.
- The remaining packets are flushed and, after receiving all the acknowledgments, the NameNode is notified that the write to the file is completed.
Apache YARN (Yet Another Resource Negotiator)
YARN is Hadoop’s cluster resource management system. It provides provides APIs for requesting and working with cluster resources to be used not by user code, but for higher level APIs, like MapReduce v2, Spark, Tez…
YARN separates resource management and job scheduling/monitoring into separate daemons. In Hadoop 1.x these two functions were performed by the JobScheduler, that implies a bottleneck for scaling the Hadoop nodes in the cluster.
YARN Components
There are five major component types in a YARN cluster:
- Resource Manager (RM): a global per-cluster daemon that is solely responsible for allocating and managing resources available within the cluster.
- Node Manager (NM): a per-node daemon that is responsible for creating, monitoring, and killing containers.
- Application Master (AM): This is a per-application daemon whose duty is the negotiation of resources from the ResourceManager and to work with the NodeManager(s) to execute and monitor the tasks.
- Container: This is an abstract representation of a resource set that is given to a particular application: memory and cpu. It’s a computational unit (one node runs several containers, but a container cannot cross a node boundary). The AM is a specialized container that is used to bootstrap and manage the entire application’s life cycle.
- Application Client: it submits applications to the RM and it specifies the type of AM needed to execute the application (for instance, MapReduce).
Anatomy of a YARN Request
These are the steps involved in the submission of a job to the YARN framework.
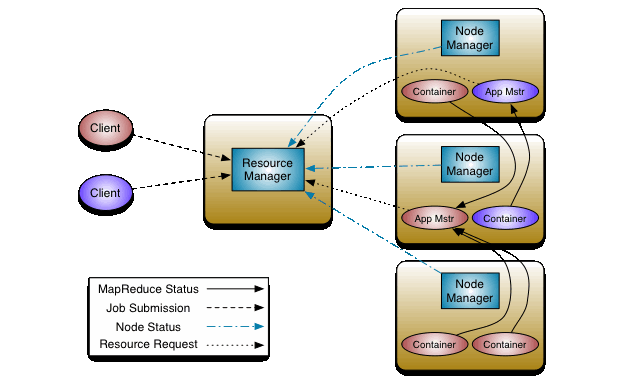
YARN architecture
- The client submits a job to the RM asking to run an AM process (Job Submission in the picture above).
- The RM looks for resources to acquire a container on a node to launch an instance of the AM.
- The AM registers with the RM to enable the client to query the RM for details about the AM.
- Now the AM is running, and it could run the computation returning the result to the client, or it could request more containers to the RM to run a distributed computation (Resource Request in the picture above)
- The application code executing in the launched container (tasks) reports its status to the AM through an application-specific protocol (MapReduce status in the picture above, that it’s assuming that the YARN application being executed is MapReduce).
- Once the application completes execution, the AM deregisters with the RM, and the containers used are released back to the system.
This process applies for each client that submits jobs. In the picture above there are two clients (the red one and the blue one)
Hadoop first program: WordCount MapReduce
MapReduce is a paradigm for data processing that uses two key phases:
- Map: it performs a transformation on input key-value pairs to generate intermediate key-value pairs.
- Reduce: it performs a summarize function on intermediate key-value groups to generate the final output of key-value pairs.
- The groups that are the input of the Reduce phase are created by sorting the output of the Map phase in an operation called as Short/Shuffle (in YARN, is an auxiliary service)
Writing the program
For writing a MapReduce program in Java for running it in Hadoop you need to provide a Mapper class, a Reducer class, and a driver program to run a job.
Let’s begin with the Mapper class, it will separate each word with a count of 1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable ONE = new IntWritable(1); private Text word = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, ONE); } } } |
Highlights here are the parameters of the Mapper class, in this case:
- The input key, a long that will be ignored
- The input value, a line of text
- The output key, the word to be counted
- The output value, the count for the word, always one, as we said before.
As you can see, instead of using Java types, it’s better to use Hadoop basic types that are optimized for network serialization (available in the org.apache.hadoop.io package)
The basic approach is to override the map() method and make use of the key and value input parameters, as well as the instance of a Context to write the output to: the words with its count (one, for the moment being)
Let’s continue with the Reducer class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } |
The intermediate result from the Mapper will be partitioned by MapReduce in such a way that the same reducer will receive all output records containing the same key. MapReduce will also sort all the map output keys and will call each reducer only once for each output key along with a list of all the output values for this key.
Thus, to write a Mapper class, you override the method reduce that has as parameters the only key, the list of values as an iterable and an instance of the Context to write the final result to.
In our case, the reducer will sum the count that each words carry (always one) and it will write the result to the context.
Finally, the Driver class, the class that runs the MapReduce job.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class WordCountDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] myArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (myArgs.length != 2) { System.err.println("Usage: WordCountDriver <input path> <output path>"); System.exit(-1); } Job job = Job.getInstance(conf, "Classic WordCount"); job.setJarByClass(WordCountDriver.class); FileInputFormat.addInputPath(job, new Path(myArgs[0])); FileOutputFormat.setOutputPath(job, new Path(myArgs[1])); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //job.setMapOutputKeyClass(Text.class); //job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
First, create a Hadoop Configuration (the default values are enough for this example) and use the GenericOptionsParser class to parse only the generic Hadoop arguments.
To configure, submit and control the execution of the job, as well as to monitor its progress, use a Job object. Take care of configuring it (via its set() methods) before submitting the job or an IllegalStateException will be thrown.
In a Hadoop cluster, the JAR package will be distributed around the cluster, to allow Hadoop to locate this JAR we pass a class in the Job ’s setJarByClass() method.
Next, we specify the input and output paths by calling the static addInputPath() (or setInputPaths) method on FileInputFormat() (with a file, directory or file pattern) and the static setOutputPath() method on FileOutputFormat (with a non-existing directory, in order to avoid data loss from another job) respectively.
Then, the job is configured with the Mapper class and the Reducer class.
There is no need for specifying the map output types because they are the same than the ones produced by the Reducer class, but we need to indicate the output types for the reduce function.
Finally, the waitForCompletion() method on Job submits the job and waits for it to finish. The argument is a flag for verbosity in the generated output. The return value indicates success (true) or failure (false). We use it for the the program’s exit code (0 or 1).
Running the program
The source code is available at github. You can download it, go to the directory and just run the next commands:
|
1 2 3 |
$ mvn clean install $ export HADOOP_CLASSPATH=target/mapreduce-0.0.1-SNAPSHOT.jar $ hadoop com.malsolo.hadoop.mapreduce.WordCountDriver data/the_constitution_of_the_united_states.txt out |
You will see something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
15/02/25 15:30:47 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 15/02/25 15:30:47 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 15/02/25 15:30:47 INFO input.FileInputFormat: Total input paths to process : 1 15/02/25 15:30:47 INFO mapreduce.JobSubmitter: number of splits:1 15/02/25 15:30:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local284822998_0001 15/02/25 15:30:47 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 15/02/25 15:30:47 INFO mapreduce.Job: Running job: job_local284822998_0001 15/02/25 15:30:47 INFO mapred.LocalJobRunner: OutputCommitter set in config null 15/02/25 15:30:47 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Waiting for map tasks 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Starting task: attempt_local284822998_0001_m_000000_0 15/02/25 15:30:48 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 15/02/25 15:30:48 INFO mapred.MapTask: Processing split: file:.../mapreduce/data/the_constitution_of_the_united_states.txt:0+45119 15/02/25 15:30:48 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 15/02/25 15:30:48 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 15/02/25 15:30:48 INFO mapred.MapTask: soft limit at 83886080 15/02/25 15:30:48 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 15/02/25 15:30:48 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 15/02/25 15:30:48 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 15/02/25 15:30:48 INFO mapred.LocalJobRunner: 15/02/25 15:30:48 INFO mapred.MapTask: Starting flush of map output 15/02/25 15:30:48 INFO mapred.MapTask: Spilling map output 15/02/25 15:30:48 INFO mapred.MapTask: bufstart = 0; bufend = 75556; bufvoid = 104857600 15/02/25 15:30:48 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26183792(104735168); length = 30605/6553600 15/02/25 15:30:48 INFO mapred.MapTask: Finished spill 0 15/02/25 15:30:48 INFO mapred.Task: Task:attempt_local284822998_0001_m_000000_0 is done. And is in the process of committing 15/02/25 15:30:48 INFO mapred.LocalJobRunner: map 15/02/25 15:30:48 INFO mapred.Task: Task 'attempt_local284822998_0001_m_000000_0' done. 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Finishing task: attempt_local284822998_0001_m_000000_0 15/02/25 15:30:48 INFO mapred.LocalJobRunner: map task executor complete. 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Waiting for reduce tasks 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Starting task: attempt_local284822998_0001_r_000000_0 15/02/25 15:30:48 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 15/02/25 15:30:48 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1bd34bf7 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10 15/02/25 15:30:48 INFO reduce.EventFetcher: attempt_local284822998_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 15/02/25 15:30:48 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local284822998_0001_m_000000_0 decomp: 90862 len: 90866 to MEMORY 15/02/25 15:30:48 INFO reduce.InMemoryMapOutput: Read 90862 bytes from map-output for attempt_local284822998_0001_m_000000_0 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 90862, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->90862 15/02/25 15:30:48 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 15/02/25 15:30:48 INFO mapred.LocalJobRunner: 1 / 1 copied. 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 15/02/25 15:30:48 INFO mapred.Merger: Merging 1 sorted segments 15/02/25 15:30:48 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 90857 bytes 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: Merged 1 segments, 90862 bytes to disk to satisfy reduce memory limit 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: Merging 1 files, 90866 bytes from disk 15/02/25 15:30:48 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 15/02/25 15:30:48 INFO mapred.Merger: Merging 1 sorted segments 15/02/25 15:30:48 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 90857 bytes 15/02/25 15:30:48 INFO mapred.LocalJobRunner: 1 / 1 copied. 15/02/25 15:30:48 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 15/02/25 15:30:48 INFO mapred.Task: Task:attempt_local284822998_0001_r_000000_0 is done. And is in the process of committing 15/02/25 15:30:48 INFO mapred.LocalJobRunner: 1 / 1 copied. 15/02/25 15:30:48 INFO mapred.Task: Task attempt_local284822998_0001_r_000000_0 is allowed to commit now 15/02/25 15:30:48 INFO output.FileOutputCommitter: Saved output of task 'attempt_local284822998_0001_r_000000_0' to file:.../out/_temporary/0/task_local284822998_0001_r_000000 15/02/25 15:30:48 INFO mapred.LocalJobRunner: reduce > reduce 15/02/25 15:30:48 INFO mapred.Task: Task 'attempt_local284822998_0001_r_000000_0' done. 15/02/25 15:30:48 INFO mapred.LocalJobRunner: Finishing task: attempt_local284822998_0001_r_000000_0 15/02/25 15:30:48 INFO mapred.LocalJobRunner: reduce task executor complete. 15/02/25 15:30:48 INFO mapreduce.Job: Job job_local284822998_0001 running in uber mode : false 15/02/25 15:30:48 INFO mapreduce.Job: map 100% reduce 100% 15/02/25 15:30:48 INFO mapreduce.Job: Job job_local284822998_0001 completed successfully 15/02/25 15:30:48 INFO mapreduce.Job: Counters: 33 File System Counters FILE: Number of bytes read=283490 FILE: Number of bytes written=809011 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 Map-Reduce Framework Map input records=872 Map output records=7652 Map output bytes=75556 Map output materialized bytes=90866 Input split bytes=175 Combine input records=0 Combine output records=0 Reduce input groups=1697 Reduce shuffle bytes=90866 Reduce input records=7652 Reduce output records=1697 Spilled Records=15304 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=8 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=525336576 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=45119 File Output Format Counters Bytes Written=17405 $ |
And you can take a look to the result using:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
$ sort -k2 -h -r out/part-r-00000 | head -20 the 663 of 494 shall 293 and 256 to 183 be 178 or 157 in 139 by 101 a 94 United 85 for 81 any 79 President 72 The 64 have 64 as 64 States, 55 such 52 State 47 $ |
Regarding this example, I have to mention a couple of things:
-
The code includes a data directory containing a text file (yes, the constitution of the USA)
- Yes, the program need some improvements for not considering the commas and something like that.
- It’s funny to see the most repeated words (the, of, shall, and, to, be, or, in, by, a) and the most important words (United, States, President)
- Due to a problem with Hadoop and IPv6, it doesn’t work with pseudistributed mode due to a connection exception (java.net.ConnectException: Call […] to localhost:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused). For this example is enough to use local mode (just recover the original core-site.xml, hdfs-site.xml, mapred-site.xml and yarn-site.xml and you can also stop the HDFS, YARN, and MapReduce daemons. See above)
Resources
- Hadoop: The Definitive Guide, 4th Edition. By Tom White (O’Reilly Media)
- Pro Apache Hadoop, 2nd Edition. By Sameer Wadkar, Madhu Siddalingaiah, Jason Venner (Apress)
- Mastering Hadoop. By Sandeep Karanth (Packt publishing)
- Hadoop in Practice, Second Edition. By Alex Holmes (Manning publications)
- Hadoop in Action, Second Edition. By Chuck P. Lam and Mark W. Davis (Manning publications)
- Hadoop – Just the Basics for Big Data Rookies. By Adam Shook (SpringDeveloper YouTube channel)
- Getting started with Spring Data and Apache Hadoop. By Thomas Risberg, Janne Valkealahti (SpringDeveloper YouTube channel)
- Hadoop 201 — Deeper into the Elephant. By Roman Shaposhnik (SpringDeveloper YouTube channel)
- Hadoop MapReduce Next Generation – Setting up a Single Node Cluster.
- The File System (FS) shell
- Primeros pasos con Hadoop: instalación y configuración en Linux. By Juan Alonso Ramos (Adictos al trabajo)
- How-to: Install a Virtual Apache Hadoop Cluster with Vagrant and Cloudera Manager. By Justin Kestelyn (@kestelyn Cloudera blog()
- How to build a Hadoop VM with Ambari and Vagrant. By Saptak Sen (Hortonworks blog)
- Hadoop HDFS Data Flow IO Classes. By Shrey Mehrotra (Hadoop Ecosystem : Hadoop 2.x)