
Spark Introduction
Apache Spark is a cluster computing platform designed to be fast, expresive, high level, general-purpose, fault-tolerante and compatible with Hadoop (Spark can work directly with HDFS, S3 and so on). Spark can also be defined as a framework for distributed processing and analisys of big amounts of data. People from databricks (the company behind Spark) called it a distributed executing engine for large scale analytics.
Spark improves efficiency over Hadoop because it uses in-memory computing primitives. According to the Apache Spark site, it can run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
It also claims to improve usability through rich Scala, Python and Java APIs as well as an interactive shell, in Scala and Python. Spark is written in Scala.
Spark Architecture
Spark has three main components
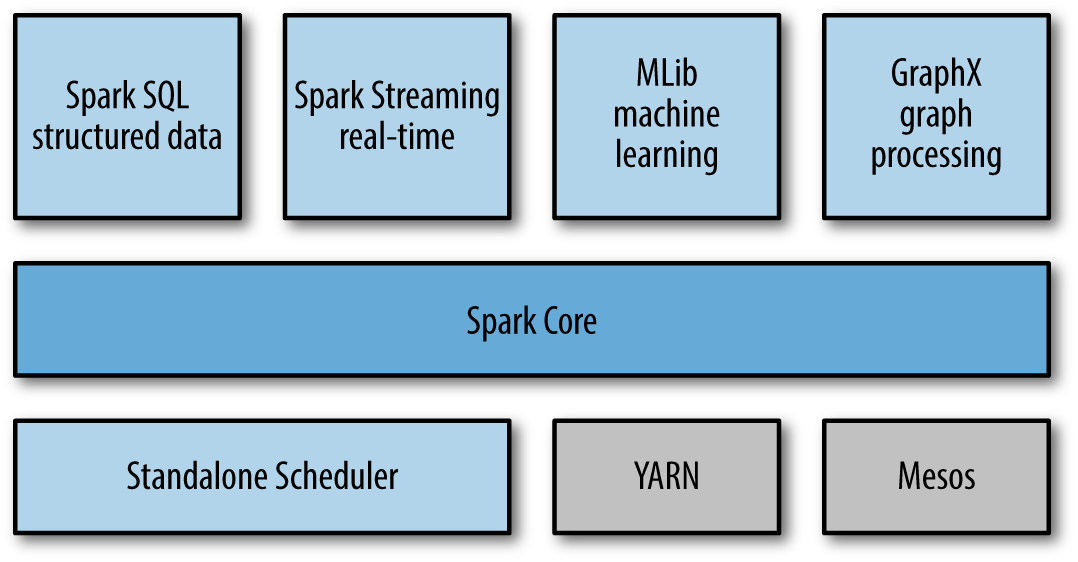
Apache Spark stack
Spark Core (API)
A high level programming framework that allows programmers to focus on the logic and not the plumbing of distributing programming, that is, the steps to be done without worrying of coordinating tasks, networking of so on.
These steps are define by RDD (Resilient Distributed Datasets), the main programming abstraction that represent a collection of items distributed across many compute nodes that can be manipulated in parallel.
Spark clustering
Spark itself doesn’t manage the cluster, but it supports three cluster managers:
- Standalone: a simple cluster manager included in Spark itself called the Standalone Scheduler.
- Hadoop YARN: see my introduction to Apache Hadoop.
- Apache Mesos.
Spark stack
Finally, Spark provides high level specialized components that are closely integrated in order to provide one great platform.
The current components are:
- Spark SQL: for querying data via SQL.
- Spark Streaming: for real-time processing of live streams of data.
- GraphX: a library for manipulating graphs and performing graph-parallel computations.
- MLLib: a library for machine learning providing algorithms for doing so (classification, regression, …)
Spark Usage
There are two ways to work with Spark:
- The Spark interactive shells
- Spark standalone applications
Spark Shell
It’s an interactive shell from the command line that has two implementations, one in Python and the other in Scala, an RPEL that is very useful for learning the API or for data exploration.
Spark’s shells allow you to interact with data not only on your single machine, but on disk or in memory across many machines, thanks to the distributed nature of Spark.
Spark Applications
The other way to work with Spark is by creating standalone applications either in Python, Scala or Java. Use them for large scale data processing.
Spark main concepts
Driver program
It’s the program that launches the distributed operations on a cluster.
The Spark shell is a driver program.
The application that you write, with its main function that defines de datasets and applies operations on them is a driver program.
Spark Context (sc)
It’s the main entry point to the Spark API.
When using the shell, a preconfigured SparkContext is automatically created and it’s available in the variable called sc.
When writing applications, the first thing that you need to create is your own instance of the SparkContext.
Resilient Distributed Dataset (RDD)
The goal of Spark is to allow you to operate in datasets in a single machine and that these operations work in the same way in a distributed cluster.
For achieving this, Spark offers the Resilient Distributed Dataset (RDD), they are immutable collections (dataset) of objects that Spark distributes (distributed) through the cluster. They are loaded from a source of data and, since they are immutable, RDDs are also created as a result of transformation on existing RDDs (map, filters, etc.). Finally, Spark automatically rebuilds them in a node if there is a failure in another node (resilient)
There are two types of RDD operations on RDDs:
- Transformations: lazy operations to build RDDs based on the current RDD.
- Actions: return a result or write the RDD to storage. It implies a computation that actually applies the pending transformation that were lazily defined.
In the Spark jargon, this is called a Direct Acyclic Graph (DAG) of operations. The RDDs track the series of transformations used to build them by maintaining a pointer to its parents.
Spark Installation
Go to https://spark.apache.org/downloads.html and then:
- Choose a Spark release (1.2.1 is the last at the time of this writing)
- Choose a package type: select the package type of “Pre-built for Hadoop 2.4 and later”
- Choose a download type: Direct Download is OK, but the default Apache Mirror works well.
- Click on the link after Download Spark, for instance spark-1.2.1.tgz, to download Spark.
Unpack the downloaded file and move into that directory in order to use the interactive shell:
|
1 2 |
$ tar -xf spark-1.2.0-bin-hadoop2.4.tgz $ cd spark-1.2.0-bin-hadoop2.4 |
Using the Shell
The Python version of the Spark shell is available via the command bin/pyspark and the Scala version of the shell by using bin/spark-shell.
Note: the shell accept code completion with the Tab key.
Let’s try the Scala shell:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
$ bin/spark-shell Spark assembly has been built with Hive, including Datanucleus jars on classpath Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 15/02/26 17:23:45 INFO SecurityManager: Changing view acls to: Javier 15/02/26 17:23:45 INFO SecurityManager: Changing modify acls to: Javier 15/02/26 17:23:45 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Javier); users with modify permissions: Set(Javier) 15/02/26 17:23:45 INFO HttpServer: Starting HTTP Server 15/02/26 17:23:45 INFO Utils: Successfully started service 'HTTP class server' on port 46130. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.2.1 /_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_31) Type in expressions to have them evaluated. Type :help for more information. 15/02/26 17:23:50 WARN Utils: Your hostname, xxx resolves to a loopback address: 127.0.1.1; using 192.168.2.49 instead (on interface eth0) 15/02/26 17:23:50 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 15/02/26 17:23:50 INFO SecurityManager: Changing view acls to: Javier 15/02/26 17:23:50 INFO SecurityManager: Changing modify acls to: Javier 15/02/26 17:23:50 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Javier); users with modify permissions: Set(Javier) 15/02/26 17:23:51 INFO Slf4jLogger: Slf4jLogger started 15/02/26 17:23:51 INFO Remoting: Starting remoting 15/02/26 17:23:51 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@xxx.malsolo.lan:55248] 15/02/26 17:23:51 INFO Utils: Successfully started service 'sparkDriver' on port 55248. 15/02/26 17:23:51 INFO SparkEnv: Registering MapOutputTracker 15/02/26 17:23:51 INFO SparkEnv: Registering BlockManagerMaster 15/02/26 17:23:52 INFO DiskBlockManager: Created local directory at /tmp/spark-1420fe71-6907-408a-b44c-9547ba1a2c49/spark-909fad01-a3df-484b-bd30-1ea6006396e9 15/02/26 17:23:52 INFO MemoryStore: MemoryStore started with capacity 265.1 MB 15/02/26 17:23:52 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/02/26 17:23:52 INFO HttpFileServer: HTTP File server directory is /tmp/spark-82586699-a230-47e4-8148-2cc4dcc741ec/spark-72f09be4-797a-4612-a845-e4fd1e578e76 15/02/26 17:23:52 INFO HttpServer: Starting HTTP Server 15/02/26 17:23:52 INFO Utils: Successfully started service 'HTTP file server' on port 41493. 15/02/26 17:23:53 INFO Utils: Successfully started service 'SparkUI' on port 4040. 15/02/26 17:23:53 INFO SparkUI: Started SparkUI at http://xxx.malsolo.lan:4040 15/02/26 17:23:53 INFO Executor: Starting executor ID on host localhost 15/02/26 17:23:53 INFO Executor: Using REPL class URI: http://192.168.2.49:46130 15/02/26 17:23:53 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@xxx.malsolo.lan:55248/user/HeartbeatReceiver 15/02/26 17:23:53 INFO NettyBlockTransferService: Server created on 40938 15/02/26 17:23:53 INFO BlockManagerMaster: Trying to register BlockManager 15/02/26 17:23:53 INFO BlockManagerMasterActor: Registering block manager localhost:40938 with 265.1 MB RAM, BlockManagerId(, localhost, 40938) 15/02/26 17:23:53 INFO BlockManagerMaster: Registered BlockManager 15/02/26 17:23:53 INFO SparkILoop: Created spark context.. Spark context available as sc. scala> |
To exit either shell, press Ctrl-D.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
scala> Stopping spark context. 15/02/26 17:27:40 INFO SparkUI: Stopped Spark web UI at http://xxx.malsolo.lan:4040 15/02/26 17:27:40 INFO DAGScheduler: Stopping DAGScheduler 15/02/26 17:27:41 INFO MapOutputTrackerMasterActor: MapOutputTrackerActor stopped! 15/02/26 17:27:41 INFO MemoryStore: MemoryStore cleared 15/02/26 17:27:41 INFO BlockManager: BlockManager stopped 15/02/26 17:27:41 INFO BlockManagerMaster: BlockManagerMaster stopped 15/02/26 17:27:41 INFO SparkContext: Successfully stopped SparkContext 15/02/26 17:27:41 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 15/02/26 17:27:41 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 15/02/26 17:27:41 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down. $ |
It’s possible to control the verbosity of the logging by creating a conf/log4j.properties file (use the existing conf/log4j.properties.template, Currently, Spark uses log4j 1.2.17, so you can find more details at Apache log4j™ 1.2 website.) and then changing the line:
log4j.rootCategory=INFO, console
To:
log4j.rootCategory=WARN, console
Now, with the shell we can try some commands like examining the sc variable, create RDDs, filtering them and so on.
|
1 2 3 4 5 6 7 8 9 10 11 |
scala> sc res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@76af34b5 scala> val lines = sc.textFile("README.md") lines: org.apache.spark.rdd.RDD[String] = README.md MappedRDD[1] at textFile at :12 scala> lines.count() res1: Long = 98 scala> lines.first() res2: String = # Apache Spark |
There is an INFO message that informs of the URL of the Spark UI (INFO SparkUI: Started SparkUI at http://[ipaddress]:4040), so you can use it to see information about the tasks and clusters.
Spark UI
Spark Operations
Once we have the Spark shell, let’s use it to take a look to the available operations before we dive into creating applications.
Creating RDDs
You can turn an existing collection into a RDD (parallelize it), you can load an external file (several formats: text, JSON, CSV, SequenceFiles, objects) or even existing Hadoop InputFormat (with sc.hadoopFile())
|
1 2 3 4 5 6 7 |
scala> val numbers = sc.parallelize(List(1,2,3)) numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:12 scala> val lines = sc.textFile("README.md") lines: org.apache.spark.rdd.RDD[String] = README.md MappedRDD[2] at textFile at <console>:12 scala> |
Transformations
As we said earlier, transformations are lazy evaluated operations on RDDs that return a new RDD.
You can pass each element through a function (with map()) or keep elements that pass a predicate (with filter()) or produce zero or more elements for each element (with flatMap()) and so on.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
scala> val squares = numbers.map(x => x*x) squares: org.apache.spark.rdd.RDD[Int] = MappedRDD[3] at map at <console>:14 scala> val spark = lines.filter(line => line.contains("Spark")) spark: org.apache.spark.rdd.RDD[String] = FilteredRDD[4] at filter at <console>:14 scala> val sequences = numbers.flatMap(x => 1 to x) sequences: org.apache.spark.rdd.RDD[Int] = FlatMappedRDD[5] at flatMap at <console>:14 scala> val words = lines.flatMap(line => line.split(" ")) words: org.apache.spark.rdd.RDD[String] = FlatMappedRDD[6] at flatMap at <console>:14 scala> |
Actions
They are the operations that return a final value to the driver program or write data to an external storage system that result in the evaluation of the transformations in the RDD.
For instance, retrieve the contents (collect()), return the first n elements (take()), count the number of elements (count()), combine elements with an associative function (reduce()) or write elements to a text file (saveAsTextFile())
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
scala> sequences.collect() res0: Array[Int] = Array(1, 1, 2, 1, 2, 3) scala> squares.take(2) res1: Array[Int] = Array(1, 4) scala> words.count() res2: Long = 524 scala> numbers.reduce((x, y) => x + y) res4: Int = 6 scala> spark.saveAsTextFile("borrar.txt") scala> |
Key/Value Pairs
There is a special type of RDD, Pair RDDs, that that contain elements that are tuples, that is, a key-value pair, being key and value of any type.
They are very useful for perform aggregations, grouping, counting. They can be obtained from some initial ETL (extract, transform, load) operations.
The pair RDDS can be partitioned across nodes for improving speed by allowing similar keys to be accesible on the same node.
Regarding operations, Spark offers special operation for Pair RDDs that allow you to act on each key in parallel, for instance, reduceByKey() to aggregate data by key, join() to merge two RDDs by grouping elements with the same key, or even sortByKey().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
scala> val pets = sc.parallelize(List(("cat", 1), ("dog", 1), ("cat", 2))) pets: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[8] at parallelize at <console>:12 scala> pets.collect() res12: Array[(String, Int)] = Array((cat,1), (dog,1), (cat,2)) scala> pets.reduceByKey((a, b) => a + b).collect() res9: Array[(String, Int)] = Array((dog,1), (cat,3)) scala> pets.groupByKey().collect() res10: Array[(String, Iterable[Int])] = Array((dog,CompactBuffer(1)), (cat,CompactBuffer(1, 2))) scala> pets.sortByKey().collect() res11: Array[(String, Int)] = Array((cat,1), (cat,2), (dog,1)) scala> |
Now let’s use the Shell to see how easily you can implement the MapReduce WordCount example in a single line:
|
1 2 3 4 5 6 |
scala> val counts = lines.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((x, y) => x + y) counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[18] at reduceByKey at <console>:14 scala> counts.collect() res16: Array[(String, Int)] = Array((package,1), (this,1), (Because,1), (Python,2), (cluster.,1), (its,1), ([run,1), (general,2), (YARN,,1), (have,1), (pre-built,1), (locally.,1), (changed,1), (locally,2), (sc.parallelize(1,1), (only,1), (several,1), (This,2), (basic,1), (first,1), (documentation,3), (Configuration,1), (learning,,1), (graph,1), (Hive,2), (["Specifying,1), ("yarn-client",1), (page](http://spark.apache.org/documentation.html),1), ([params]`.,1), (application,1), ([project,2), (prefer,1), (SparkPi,2), (<http://spark.apache.org/>,1), (engine,1), (version,1), (file,1), (documentation,,1), (MASTER,1), (example,3), (are,1), (systems.,1), (params,1), (scala>,1), (provides,1), (refer,2), (configure,1), (Interactive,2), (distribution.,1), (can,6), (build,3), (when,1), (Apache,1),... scala> |
Spark Applications
For writing a Spark Application it’s possible to use Scala, Python or Java. What I’m going to do is to use Java 8 to take advantage of the new features of the language in order to have a less verbose syntax.
Word count Java application
First, use the appropriate dependency. For instance, with maven:
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.2.1</version> </dependency> |
Then, you have to instantiate your own SparkContext, and it’s done via a SparkConf object. We use the minimal configuration: a name for the cluster URL (“local” to use a local cluster) and an application name to identify the application on the cluster:
|
1 2 |
SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count with Spark"); JavaSparkContext sc = new JavaSparkContext(conf); |
Now, before writing Java, code it’s necessary to explain the differences with Scala.
Spark is written in Scala and it takes full advantage of its features. But Java lacks of some of them. So Spark provides alternatives with interfaces or concrete classes.
Let’s see the Word Count example in Spark written in Scala:
|
1 2 3 4 5 |
val file = spark.textFile("file") val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("out") |
Java didn’t accept functions as parameters, so Spark provides interfaces in the org.apache.spark.api.java.function package to be implemented, either as anonymous inner classes or as named classes, to be passed as arguments of the functions (flatMap(), map(), reduceByKey(), …)
In our case, these are the functions that are needed:
- FlatMapFunction
call(T t) to return zero or more output records from each input record (t). - PairFunction
- Function2
Java doesn’t have a native implementation of Tuple (as Lukas Eder said On a side-note at here “Why the JDK doesn’t ship with built-in tuples like C#’s or Scala’s escapes me.”, in other words, “Functional programming without tuples is like coffee without sugar: A bitter punch in your face.”)
For that reason, Spark provides several implementations for Tuple in the scala package.
But, Java has evolved, and now functions are first class citizens, so it’s possible to pass them as parameters for other functions, thus it’s very easy to write the Java 8 version of the word count in Spark using lambdas (since the provided interfaces have a sole public method. And the result is almost as clear as the Scala version)
|
1 2 3 4 5 |
JavaRDD<String> lines = sc.textFile("file"); JavaPairRDD<String, Integer> counts = lines.flatMap(line -> Arrays.asList(line.split(" "))) .mapToPair(word -> new Tuple2<String, Integer>(word, 1)) .reduceByKey((x, y) -> x + y); counts.saveAsTextFile("out"); |
The complete source code is available at GitHub.
Build and run
Now, we only have to build the project (with maven) and submit it to Spark (with bin/spark-submit). From the root directory of the application (note: the out directory must not exists, so remove it previously if you need so with rm -r out):
|
1 2 |
$ mvn clean install $ ~/Applications/spark-1.2.1-bin-hadoop2.4/bin/spark-submit --class com.malsolo.spark.examples.WordCount target/spark-examples-0.0.1-SNAPSHOT.jar |
Finally, we can see the results to compare with the ones obtained using Hadoop:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
$ cat out/part-00000 | grep President (President,,26) (President,72) (President.,8) (Vice-President,5) (Vice-President,,5) (Vice-President;,1) (President;,3) (Vice-President.,1) $ cat out/part-00000 | grep United (United,85) $ cat out/part-00000 | grep State (State,47) (States,46) (States.",1) (State.,6) (States,,55) (State,,20) (States:,2) (States.,8) (Statement,1) (States;,13) (State;,4) |
Shared Variables
Spark closures and the variables they use are sent separately to the tasks running on the cluster, thus the variables created in the driver program are recieved in the tasks as a new copy, so updates on these copies are not propagated back to the driver.
Spark has two kinds of shared variables, accumulators and broadcast variables, to solve that problem as well as for solving issues related with the amount of data that is sent across the cluster.
Accumulators
Variables that can be used to aggregate values from worker nodes back to the driver program. In a nutshell:
- They are created with SparkContext.accumulator(initialValue) that returns an org.apache.spark.Accumulator[T] (with T, the type of initialValue)
- Worker code adds values with += in Scala or the function add() in Java.
- The driver program can access with value in Scala or value()/setValue() in Java (accessing from worker code throws an exception)
- The right value will be obtained after calling an action (remember that transformations are lazy operations)
Spark has built-in support for accumulators of type Integer, but you can create custom Accumulators by extending AccumulatorParam.
Let’s see an example that counts the empty lines in the file that we use to count words:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count with Spark"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile(INPUT_FILE_TEXT); final Accumulator<Integer> blankLines = sc.accumulator(0); @SuppressWarnings("resource") JavaPairRDD<String, Integer> counts = lines.flatMap(line -> { if ("".equals(line)) { blankLines.add(1); } return Arrays.asList(line.split(" ")); }) .mapToPair(word -> new Tuple2<String, Integer>(word, 1)) .reduceByKey((x, y) -> x + y); counts.saveAsTextFile(OUTPUT_FILE_TEXT); System.out.println("Blank lines: " + blankLines.value()); sc.close(); } |
- In line 5 we create an Accumulator
initialized to 0 - In lines 11 to 16 we modify the FlatMapFunction to add 1 if the input line is empty
- In line 22 we print the value of the content. After the saveAsTextFile() action.
Let’s try:
|
1 2 3 4 5 6 7 8 9 10 |
$ rm -r out $ mvn clean install $ ~/Applications/spark-1.2.1-bin-hadoop2.4/bin/spark-submit --class com.malsolo.spark.examples.WordCount target/spark-examples-0.0.1-SNAPSHOT.jar Spark assembly has been built with Hive, including Datanucleus jars on classpath 15/03/02 15:26:22 WARN Utils: Your hostname, xxx resolves to a loopback address: 127.0.1.1; using yyy.yyy.y.yy instead (on interface eth0) 15/03/02 15:26:22 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 15/03/02 15:26:23 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Blank lines: 169 $ |
Broadcast variables
Shared variable to efficiently distribute large read-only values to all the worker nodes.
If you need to use the same same variable in multiple parallel operations, it’s likely you’d rather share it instead of letting Spark sends it separately for each operation.
In a nutshell:
- They are created with SparkContext.broadcast(initValue) on an object of type T that has to be Serializable.
- Access its value with value in Scala or value() in Java.
- The value shouldn’t be modified after creation, because the change will only happen in one node.
Let’s see an example with a list of words that have not to be included in the count (a short list, but enough to see the concept):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count with Spark"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile(INPUT_FILE_TEXT); final Accumulator<Integer> blankLines = sc.accumulator(0); final Broadcast<List<String>> wordsToIgnore = sc.broadcast(getWordsToIgnore()); @SuppressWarnings("resource") JavaPairRDD<String, Integer> counts = lines.flatMap(line -> { if ("".equals(line)) { blankLines.add(1); } return Arrays.asList(line.split(" ")); }) .filter(word -> !wordsToIgnore.value().contains(word)) .mapToPair(word -> new Tuple2<String, Integer>(word, 1)) .reduceByKey((x, y) -> x + y); counts.saveAsTextFile(OUTPUT_FILE_TEXT); System.out.println("Blank lines: " + blankLines.value()); sc.close(); } private static List<String> getWordsToIgnore() { return Arrays.asList("the", "of", "and", "for"); } |
- In line 9 we create the broadcast variable: a list of words to ignore. In lines 30 to 31 we only return 4 words, but it’s easy to see that the list could be big enough.
- In line 19 we access the broadcast variable with the value() method and use it in a filter method.
Resources
- Source code at GitHub
- Learning Spark. By Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia (O’Reilly Media)
- Cloudera Developer Training for Apache Spark. By Diana Carroll (Cloudera training)
- Parallel Programming with Spark (Part 1 & 2). By Matei Zaharia ((UC Berkeley AMPLab YouTube channel))
- Advanced Spark Features. By Matei Zaharia (UC Berkeley AMPLab YouTube channel)
- A Deeper Understanding of Spark Internals. By Aaron Davidson (Apache Spark YouTube channel)